From servers to serverless
Before diving into the details of implementation, let's see how files are handled in a server-based architecture and why that way is not an option when using serverless!
3-tier architecture
Before serverless, file handling was usually implemented by streaming through the backend from the storage to the visitors.
The backend has access to a private file storage, such as the local filesystem, a centralized file storage, or the main database. But this storage is not accessible to the outside world. In the case of AWS, the best practice is to create a so-called private subnet that is accessible only from the same VPC.

This is called the 3-tier architecture: The frontend is running on the visitors' machines, communicating with the backend, and the data store is hidden behind it. This yields 3 layers, each communicating only with the ones next to it.
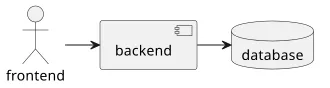
When the client requests a file, it sends the request to the backend, the backend fetches the file itself and sends back to the client. The clients have no direct access to the data store, only to the backend.
Why was this architecture used?
First, it is convenient to have only a single point of access to handle visitors and no separate service to maintain.
Second, files consume a lot of bandwidth but not much CPU on the servers. Also, it does not depend much on how slow the client is, as a slow upload consumes roughly the same amount of resources (CPU and bandwidth) as a fast one. Moving file handling to a separate service would not yield many benefits as files would still consume the same amount of resources.
As for scaling, it is only a matter of adding more servers.
- The backend is the single point of contact
- Files are streamed through the backend
Serverless architecture
Serverless architecture is fundamentally different and it does not support the streaming model of the 3-tier architecture.
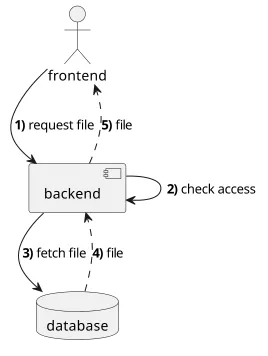
In the cloud, there is a public-facing object store that has the files. The backend function does the access control, but instead of requesting the file itself, it signs a URL which represents granted access. The client, using the resulting URL, contacts the object storage directly and gets the file.
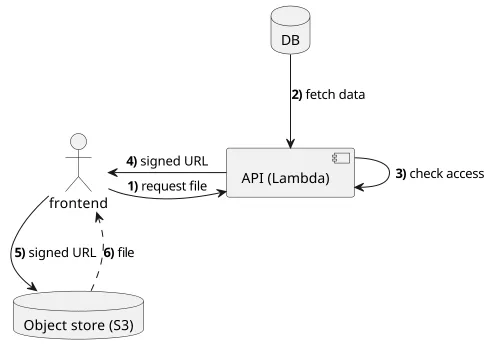
During the access control check, the backend also relies on a database that stores operational data, such as the registered users, the available files, and other data. For example, in an ecommerce app, this database stores data about which products users bought. This database is not accessible from the outside, or at least it is locked down to accept connections only from the backend. In the case of DynamoDB, the database that we'll use in the examples, that means using IAM policies to selectively grant access only to the Lambda function of the backend.
Note that the frontend does more things than before. First, it has to get the signed URL and then fetch the file. This means that migrating to signed URLs is not a transparent change.
- The backend function checks access and signs the URL
- Clients fetch the file directly from the object storage
Why streaming is not an option
Why serverless architecture has to work so different than the 3-tier architecture?
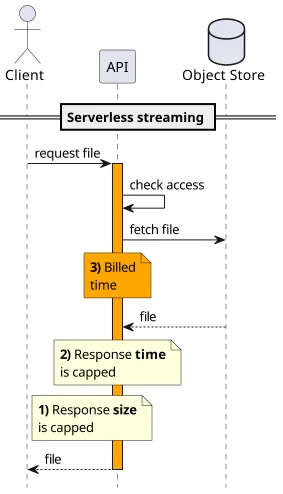
First, the response size is capped. In the case of AWS, Lambda response is limited, to 6 MB by default and 20 MB for streamed responses. This is an absolute ceiling, there is no support form to fill to increase it.
Second, there is a limit on the response time. While it's another quota that can't be increased, in practice it's not a problem: because of the response size cap the function won't run for long anyway.
But the above two reasons are limitations in AWS. There might be clouds where these aren't enforced. But streaming is still not an option because of the cost model of serverless architectures.
You pay for the execution time of the function. Even if a cloud allows returning responses of any size relying on that might be prohibitively expensive. In the case of AWS, the Lambda runtime provides buffering, so even if the function uses a streaming response it won't get stalled if the client's bandwidth is limited. But a different cloud where true streaming from the function to the client is supported, the execution time would be dependent on how fast the client can consume the bytes. A slow client would mean more expensive transfer, which is very different than the server-based model.
In practice, the hard limit on response size is the biggest problem. Serverless is all about the "quick and small" model for requests and responses and files of arbitrary sizes just don't fit into that way of thinking.
Notice the trap here. 20 MBs is not that bad, right? For example, when users can share images with each other, it might seems like an acceptable upper limit. The problem here is that this is an absolute limit: it restricts the features that can be added later. For example, maybe a professional photographer wants to share their images on the platform and complains that it returns an error. If you rely on Lambda streaming responses, then you're stuck; there is no setting you can adjust to accommodate for bigger sizes. An architectural decision made earlier puts a barrier on functionality that is significantly harder to move later.
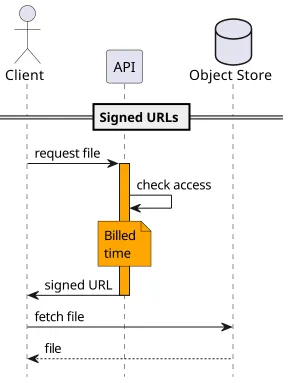
In the case of signed URLs, the file size is virtually limitless. S3 has some limits, but they are in the terabyte-range.
The function's response time is also not an issue here. The transfer itself is done by S3 which does not cap how long a download can be (at least not to any reasonable limit).
And finally, you won't pay for the duration of the download. You'll pay for the short duration when the function runs and signs the URL, then pay for the bandwidth. No extra cost for slow downloads.
With signed URLs, you retain control over access, but you lose control over the bandwidth. If you sign a URL, the client can download the file multiple times and you have no way of restricting it.